Subject: Re: First part of the time-odds experiment finished Fri Oct 08, 2021 1:26 pm
Interesting: Dragon makes better use of the extra time than Stockfish does.
My guess is that this is down to more accurate evaluation of positions. One could test this by repeating the experiment with handwritten stockfish eval v NN stockfish eval and see whether the gap remains as large.
Admin Admin
Posts : 2608 Join date : 2020-11-17 Location : Netherlands
Subject: Re: First part of the time-odds experiment finished Fri Oct 08, 2021 4:59 pm
Probably so. Komodo scales a lot better than Stockfish. It could already be concluded from the GRL at 20 cores. This is a second proof.
Uri Blass
Posts : 207 Join date : 2020-11-28
Subject: Re: First part of the time-odds experiment finished Fri Oct 08, 2021 5:19 pm
Admin wrote:
Probably so. Komodo scales a lot better than Stockfish. It could already be concluded from the GRL at 20 cores. This is a second proof.
I do not see that komodo scales a lot better than stockfish. Komodo cannot win against stockfish even with many cores based on mark young's matches.
I suspect that the bigger rating difference may be because of contempt that stockfish does not have. Note that I prefer to test stockfish developement version and not stockfish14 but I do not believe Dragon can even beat stockfish14 at long time control(something that I could expect to see at some time control if dragon komodo scales better).
Last edited by Uri Blass on Fri Oct 08, 2021 9:20 pm; edited 1 time in total (Reason for editing : I did a mistake when I explained stockfish has contempt when I meant the opposite)
mwyoung
Posts : 880 Join date : 2020-11-25 Location : USA
Subject: Re: First part of the time-odds experiment finished Fri Oct 08, 2021 9:12 pm
I know some think that this is caused by the opening book. Well if you take the book out of the equation(chess 960). You still get the same results.
I never test with books, no single chess programmer will, no rating list also except the SSDF. Here is why:
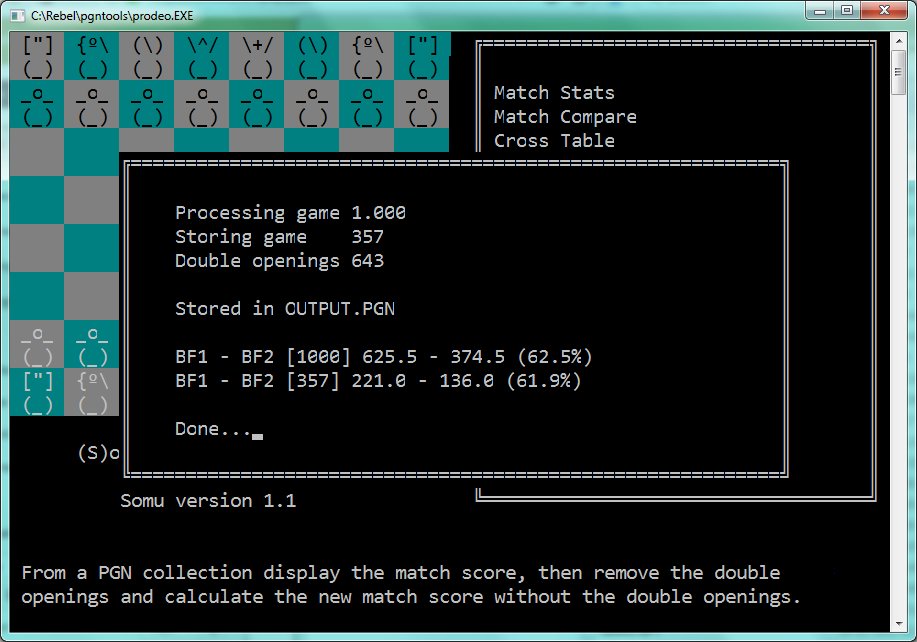
I played a quick 1000 game match, the latest SF-DEV vs SF14 with the Perfect-2021 you are using. I have an util SOMU -> Double Openings, it states:
Code:
Processing game 1.000 Storing game 656 Double openings 344
Nevertheless, the DEV version won convincingly, TC=40/10.
Code:
Score of stockfish_21-10-06 vs sf14: 145 - 54 - 801 [0.545] 1000 ... stockfish_21-10-06 playing White: 104 - 11 - 385 [0.593] 500 ... stockfish_21-10-06 playing Black: 41 - 43 - 416 [0.498] 500 ... White vs Black: 147 - 52 - 801 [0.547] 1000 Elo difference: 31.7 +/- 9.5, LOS: 100.0 %, DrawRatio: 80.1 % Finished match
BTW, I have seen much worse books.
1)Only ssdf test with own books but usually testers test with books but not when every engine use its own book. The only test without book is in FRC games Testing with Perfect-2021 is testing with books because maybe some decisive results are result of the book.
2)I see no problem with no books in normal chess and I think that it may be interesting if there are books that can improve the rating of engines relative to no book.
It is possible to avoid double opening by learning(assuming you do not like to repeat the same line that you lost with black or drew with white) but If the engines do not learn then it is possible to develop learning by the interface in the following way assuming the engines support multi-pv
Use multi-pv with 2 options in the first moves and choose a different move that the engine never got bad result with it that has the same score as the best move as fast as possible.
A bad result is a draw for white or a loss for black.
Admin Admin
Posts : 2608 Join date : 2020-11-17 Location : Netherlands
Subject: Re: First part of the time-odds experiment finished Sat Oct 09, 2021 9:21 pm
Admin wrote:
Started a match for the GRL with the 21-10-06 version.